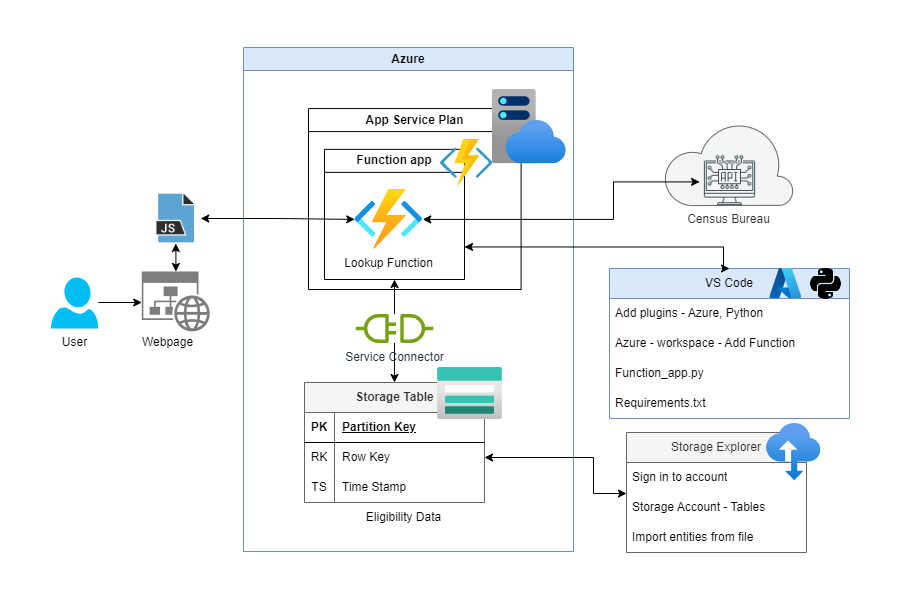
System Outline
This was an attempt to recreate the backend used in a prior project where I made analysis results available by having a static page use JavaScript to make an API call to an AWS API gateway that then passed the request over to Lambda functions that used python to parse the requests, geocode an address, and do a DynamoDB lookup before returning results.
The idea was to recreate that same architecture by using Azure functions and storage tables. In concept they are similar but I had not ever developed an Azure function and wanted to use this to learn.
In the end the result was a working system, however it suffered from considerable lag when compared to the AWS system. The time to execute the calls, lookups, and return results was between 5 and 15 seconds. Which is not responsive enough for a public facing service.
The AWS backed version can be found here: Summer Food