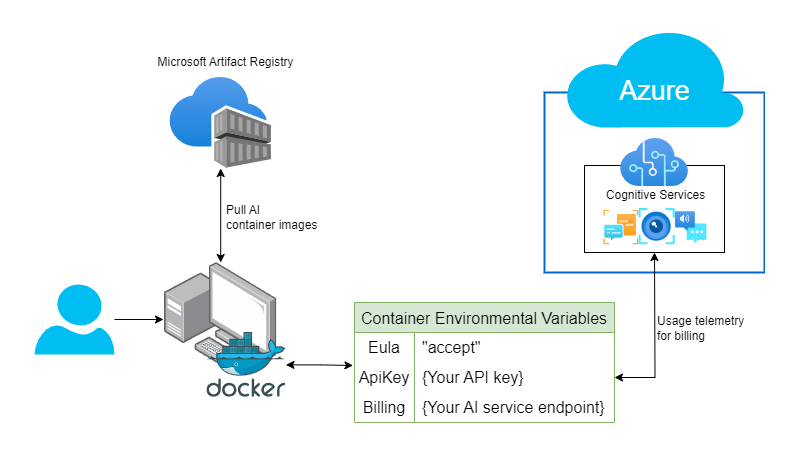
Microsoft publishes container images for many (but not all) of its Artificial Intelligence services. These images are publicly available in its Artifact Registry (a rename of the Container registry). These are intended to allow you to run AI services locally when you need to process data that is sensitive or otherwise not allowed to leave your premises.
In order to use the containers, you need to accept the end use license and point the container to an endpoint in your azure cloud with an API key that you get from creating the service in the cloud. The API endpoint and key are used to send usage statistics back to your Azure account so that you can be billed for consumption.
Implementation is not difficult, but there was a lot of time spent with the documentation to make sure the environmental variables were correct. Sometimes it appears that the containers don’t spin up correctly. Which might be due to the need to reach the endpoint or they shutdown. I don’t know if there are built in retrys. Etc. They do very nicely come with built in swagger API documentation but there are difference from how calls are made between the cloud based and the container based services. So you may need to adjust more than just endpoint location for any code that makes calls.
Privacy comes with a price
If you want to process your data in a secure way the containers are a good way to do it, but they dont offer any discount vs using the cloud-based systems. So, you are paying for your local compute and still paying the same price for the cognitive services. Small scale not a big issue, but needs consideration when looking at large scale.
Consistency
The allure of containers is that they give you consistency. They let you run complex environments without a second thought. They crash they spin up and are right back to being fresh. However, some of the AI service container seem more stable than others. There were also some that had more Environmental setting requirements that were not well documented. It give them a bit of an after thought feel.
Limited Availability
Not all AI services are available as containers. Understandably there are some limits, but it’s important to know that not everything can be done locally.
API Differences
There are differences in the way that you make calls between the cloud native and the local AI services. Which means that you may need to modify your code to the specific method you use. With good coding practices it might not be too difficult to write a single function that you could use with either. But it does mean you need to support different contexts.
Retrospective
I know I focused on the limitations, but I really like this option. This addresses a huge need in adoption of AI services. There is a big fear of sending your data out across the net, there are privacy concerns and regulations, and there are many enterprises that don’t want their data being used to train models. This avoids all of that by doing your processing on your local servers or desktops and only sending back usage details. I would love to see this type of service offered by other cloud providers as well.