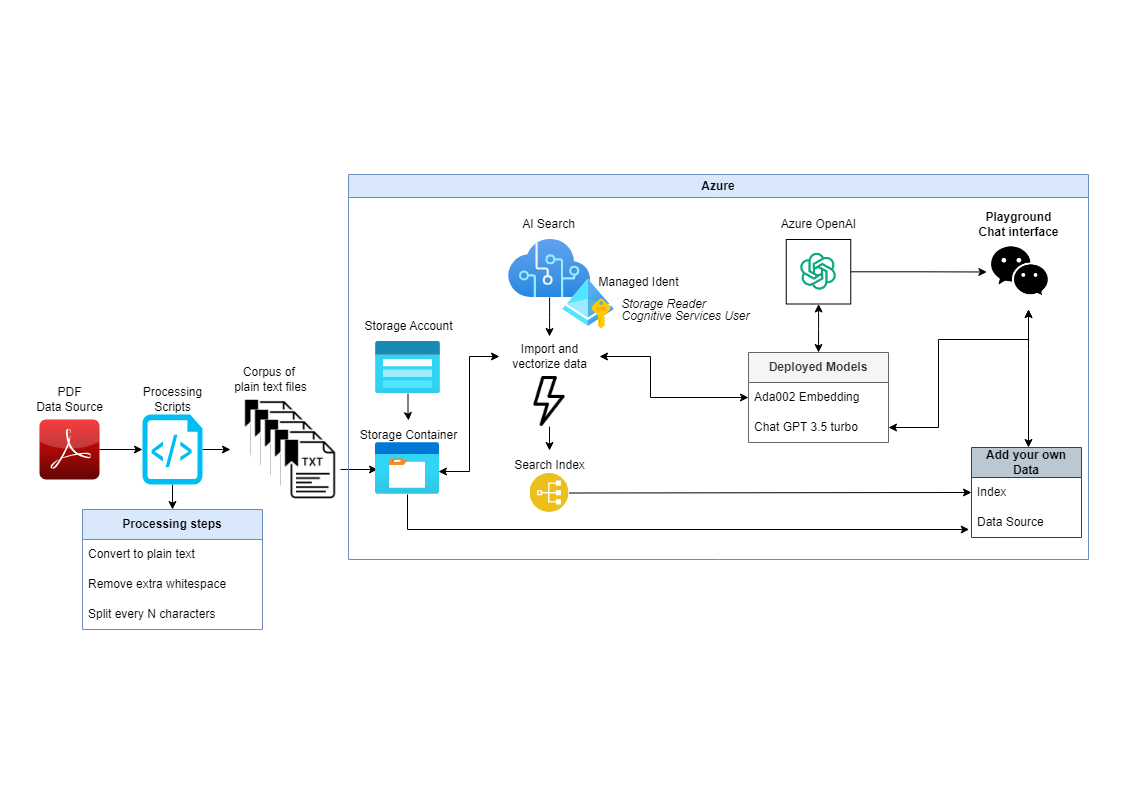
System Outline
The idea that you will be able to take any long pieces of text data like books or technical manuals and convert them into chatbots that will be able to answer your questions about them is very powerful. Microsoft’s partnership with OpenAI has made this much more possible. You can take the text and load it into storage containers and have the AI Search service periodically update the search indexes based on the files in that container. You can then use the connection to ChatGPT to send your questions, your search index, the matching files from your search index as context to ChatGPT to come up with an answer for you. This is what is known as Retrieval Augmented Generation or RAG.
You can limit the responses from ChatGPT to only information it finds in your input text. Meaning it wont hallucinate or make up additional results. This is very powerful control system when you need answers that are specific to your data and not the wider ChatGPT training set.