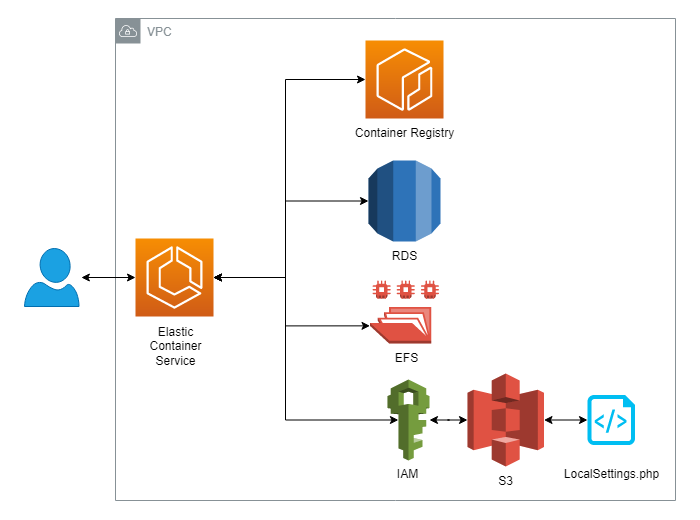
The MediaWiki foundation publishes a base container image that we take and modify though the
use of a Dockerfile and shell scripts and repackage into a new modified image. This image is
uploaded to an Elastic Container Registry (ECR) that will hold our container images
privately and allow us to call them from AWS services. In this case we are using the Elastic
Container service (ECS) which allows us to run a single container or group of containers on
either a set of compute resources (EC2) or serverless (Fargate). The container itself is
stateless and relies on a MySQL compatible relational database (RDS) for persistence of user
data and page content. For configuration files a Simple Storage Service (S3) bucket was used
to hold files that are read in at boot. To hold persistent binary files an Elastic File
System (EFS) was attached as a volume. Secrets are added in as environmental variables to
prevent key loss if files are compromised.
This was the third time implementing Mediawiki on a cloud provider and I carried forward some of the
lessons from the previous attempts. That doesn’t mean there weren’t lessons to be learned this time
around. AWS has some particular ways it wants you to implement and architect resources that differ
from the other providers. The AWS ecosystem was perhaps the most challenging to get up to speed
with, but at the same time it is also the most mature.
Carry lessons forward
The implementation of this project on Azure taught me lessons about modifications needed to
the Apache webserver and ways to avoid file system permissions with network attached
storage. The lesson here is that you can and should take lessons and apply them as you go
forward. The changes may not all be strictly necessary across providers but using the last
ending point as the start of the next makes improvement easier.
No FUSE support on Fargate
When using Azure you can mount a volume directly. When using GCP you can use gcpFUSE to
attach Filesystem in User space. AWS doesn’t offer this so you need to build up a different
set of integrations. Here the solution was to use S3 to hold the configuration files and
Elastic File System to hold the binary files.
Command line interface for S3
Since there is no FUSE support you cant attach an S3 bucket directly to the container. You
can however use the command line interface (CLI) to pull down files from S3 if you have the
correct permissions. If we parameterize the configuration file location, we can use this to
pull the file in before starting Apache
No clear visibility into EFS
The Elastic File system is perfect for sharing files across containers, it allows
multi-attach (more than one container can mount it at the same time and files get shared in
real time) but unlike an Azure Filestore or a google bucket there is no AWS portal interface
that you can use to navigate or manage the files in EFS. You can start an EC2 virtual
machine and attach it so that you can manage the files that way but it is not as ideal as
how the other providers operate.
IAM Execution roles
To access S3 you need to attach the proper permissions to the task role. Task roles are
separate from execution roles and this can cause some headaches of you are not aware of the
IAM restrictions.
Security Groups and Network Access Control Lists
AWS has a much finer grain control over access than the defaults for Azure or GCP. I had been
trying to restrict as much of the network as possible as a simple security measure but
inadvertently disabled HTTPS for ECS. This led to a long process trying to debug why it was
no longer able to pull my images from the container registry. The internal systems that read
the images require HTTPS be available to pull in your container.
AWS Metadata server
One of the configuration options that needs to be set is the IP/path to the server. This can
be tricky when the system is run in a container and the IP may be different for each
invocation or if there are multiple instances. To solve this AWS provides an internal server
with metadata that can be queried to get things like the public or private IP address of the
container.
Retrospective
Like the other wiki projects this was used as an entry into the AWS service, and it was created
before I had studied for any certifications and so the architecture is not exactly how I would set
thing sup now. This is perhaps the closest of the three to being where I might want it, but now with
a better understanding of how the Elastic Container Service functions (loosely mimics Kubernetes) I
would do more to establish autoscaling and monitoring. There is a particularly bad flaw in the way
that task definitions are stored in AWS in that environmental variables are stored in plaintext and
the templates can be depreciated but not removed. So, if you store credentials in them they will be
visible to anyone with access to the portal section. This is a good reason to switch to using a
secret or configuration manager. Which would also allow for easy rotation or revocation. There is
also room for improvement in fault tolerance with deploying across
availability zones. Finally, there is the ability to deploy containerized services using Serverless
Application Model (SAM) templates or Cloud Formation templates. It would be useful to learn to write
these in the same way that ARM templates make managing Azure resources easier.
For a first project on AWS this was very helpful in forcing me to learn the setup and configuration
of VPCs, Subnets, route tables, security groups, routing tables, and preparing me for big sections
of the Solutions architect and developer certifications.