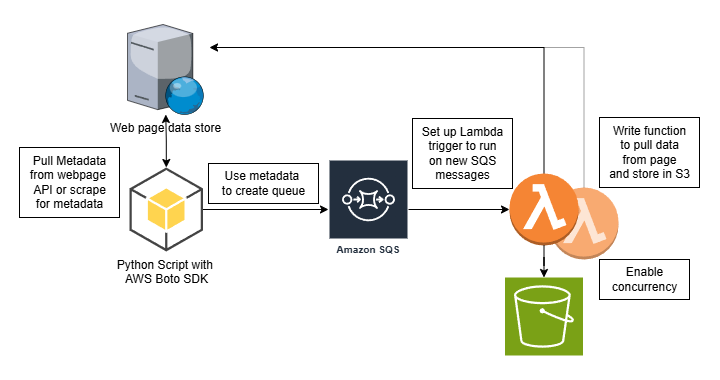
System Outline
As research starts going dark I had a need for a way to download thousands or millions of items from websites. Initial attempts were with Google Colabs and grabbing a single file at a time. However, this was too slow and time was a factor. So, I needed to find a way to keep a running list of files to download and mark them as complete when done, and also to grab as many in parallel as possible. This forced me to finally learn how to leverage queues to drive functions and actually be event driven.